General information
Distribution of data by indexes
Data from different information systems needs to be recorded in different indexes.
For example, if you have data on Linux events and Windows events, you need to split them into indexes. Writing data from different sources into one index can lead to problems in preserving the data structure.
Use a time filter when searching
Use a time range for your search that matches the purpose of the search query. For example, when searching for an event within the last hour, reduce the time range by changing the default value of Last 24 hours to Last 1 hour.
Setting up mapping
Mapping settings allow you to determine the data type of fields for indexed events. In addition to standard data types (integer, long, date, etc.), it is worth paying attention to the text and keyword types.
The text field type is parsed during indexing, but the keyword field is not. This means that text is split into individual words when indexed, allowing for a partial match. Therefore, a field of type text is used for full-text search, which uses more cluster resources. A field of type keyword is used to ensure a complete match.
Example.
In the wineventlog-* index you need to find all events by the value "logged" in the event.action field.
-
Open the search section
Main Menu-Core-Search -
Create a request
source wineventlog-*
| search event.action="logged"
| stats count by event.action
In this case, the field event.action is of type text. Therefore, the search will be performed on all events containing the value logged.
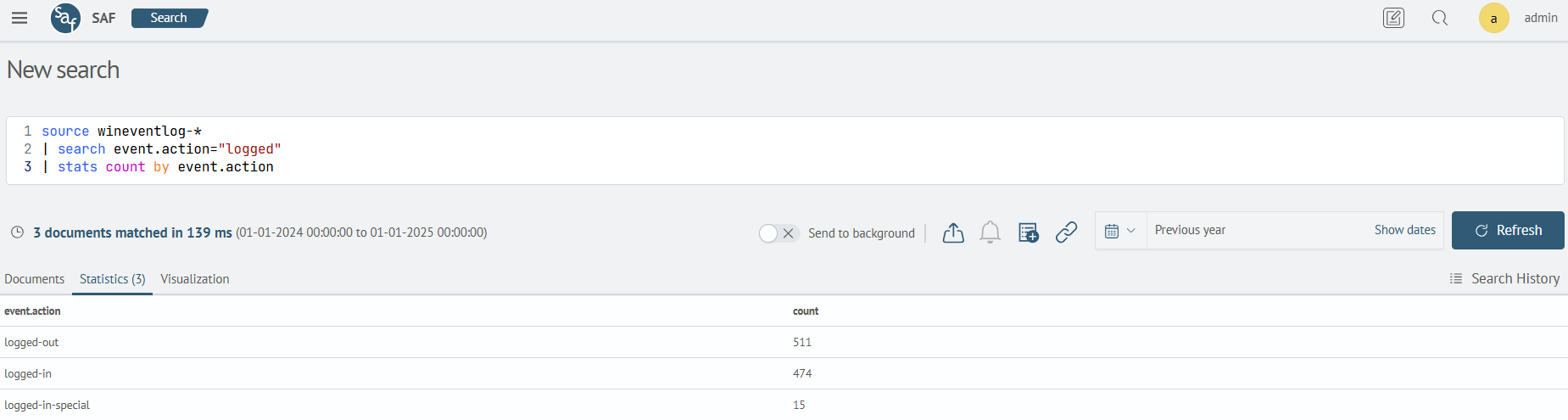
If necessary you can apply a text mapping to a field by adding .text to the field name: event.action.text.
- Search with
keywordmapping:
source wineventlog-*
| search event.action.keyword="logged"
| stats count by event.action
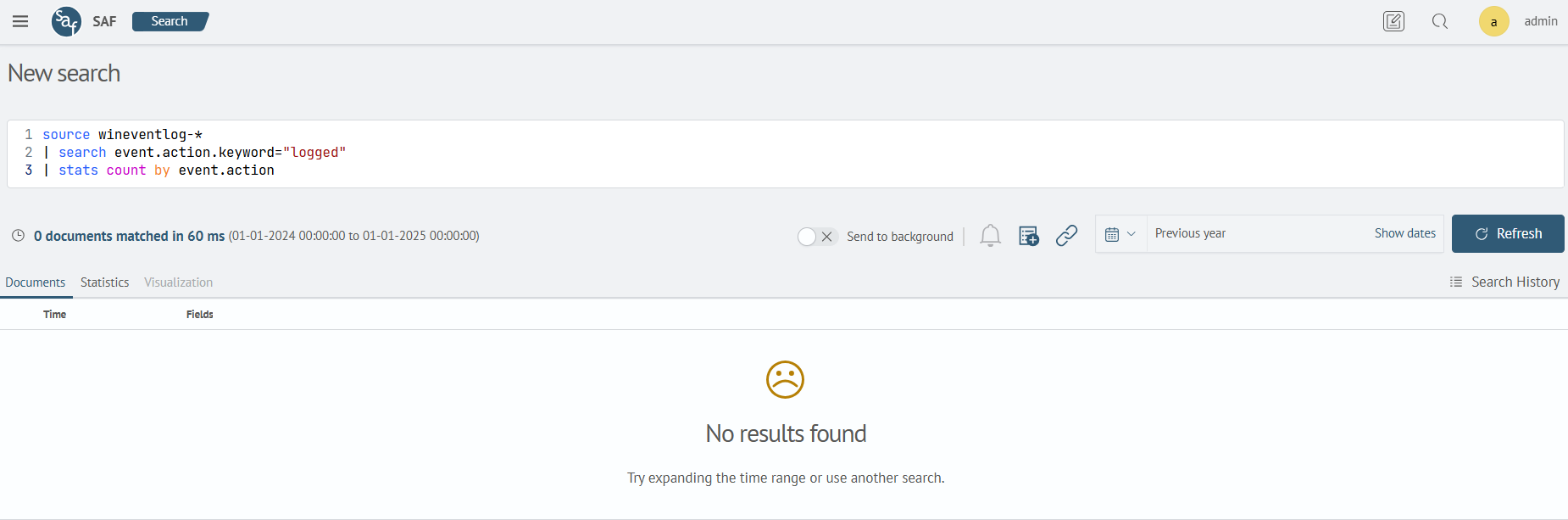
Search will not find anything. Because for keyword mapping, the search engine will look for an exact match in the search. You need to specify the exact value to search for:
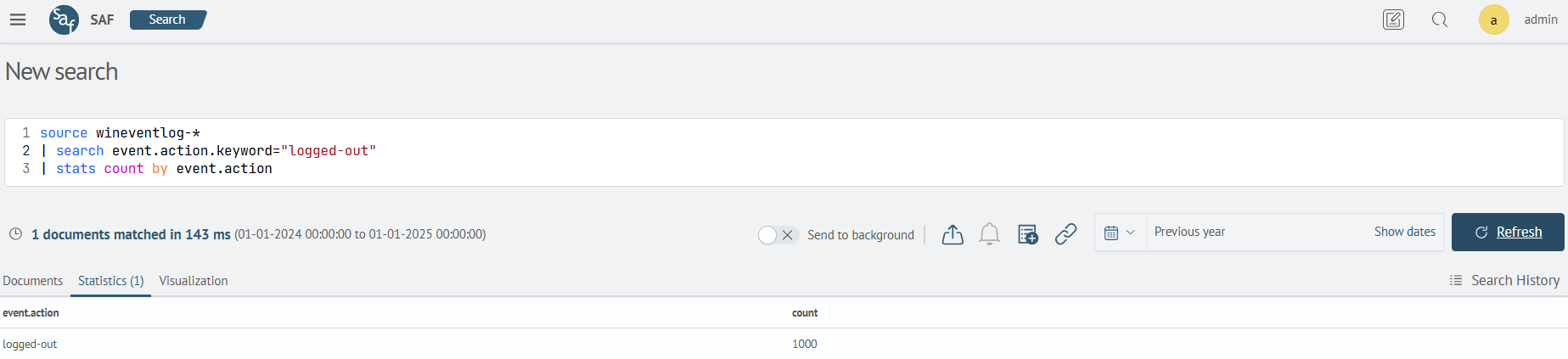
source wineventlog-*
| search event.action.keyword="logged-out"
| stats count by event.action
Now the search will find all events by exact match of the event.action field.
Setting up indexes
To distribute the index evenly across all data nodes in the cluster, you need to choose the right number of shards. Their number should be determined by the volume of indexed data. It is recommended to use a setting of 30-50 GB per shard. For example, if you plan to accumulate about 300 GB of data per day, then for such an index it is optimal to have about 10 shards.
Example configuration of an index with shards and replicas parameters:
PUT <index-name>
{
"settings": {
"number_of_shards": <number_of_shards>,
"number_of_replicas": <number_of_replicas>
}
}
Once the settings for the index are applied, they cannot be changed. To apply new settings on the same data, you need to create a new index with the necessary settings and perform indexing again.
Time-Based Index Pattern Filtering
An index pattern may match many indices, which can lead to additional overhead.
The cluster setting sme.core.resolve_index_pattern enables filtering of indices within a pattern, limiting the set of indices based on the time parameters of the search query.
Enabling the Setting
PUT _cluster/settings
{
"persistent": {
"sme.core.resolve_index_pattern": true
}
}