Frequency
Calculates the characteristic frequency of an object's actions (repetition of actions over a period of time). Used to detect anomalies, such as:
- a user launched a rarely used process
- a file with a rare file extension for the user was used
Algorithm Description
- General and temporal filters are applied to the source index data
- Each data record is brought to a common form according to the settings of the processed fields
- Data is divided by unique combinations of values of the processed fields
- Each part of the data obtained in step 3 is divided into intervals, and the number of documents in each interval is counted
- Statistics are calculated based on the number of documents for each field division
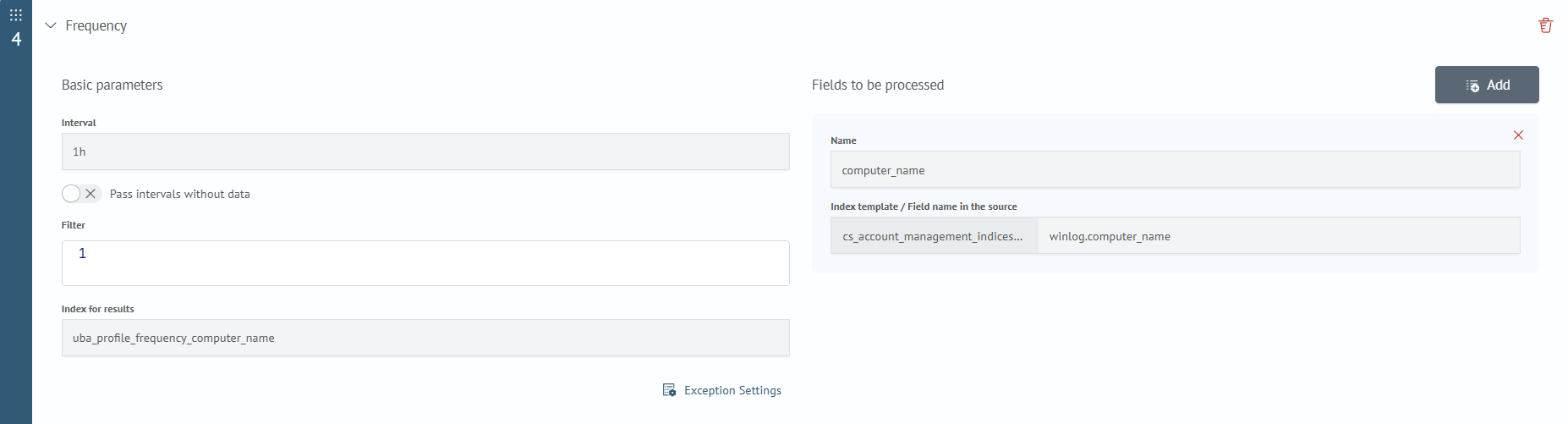
Input Parameters
- Filter - general filter for sources (using expressions from the search command)
- Index for results - index where the execution results are recorded
- Fields to be processed - mapping of source fields to result fields
- Name - the name of the field in the results index
- Index template / Field name in the source - a list of index templates and corresponding fields in them that will be extracted into the result
- Interval - the size of the time intervals into which the source data is divided.
Examples of filling:
1y- year,1M- month,1d- day,1H- hour,1m- minute,1s- second - Pass intervals without data - empty intervals are not considered in the statistics calculation
- Exception Settings — allows you to define rules for excluding data from calculations. Clicking this option opens a modal window where you can add conditions to exclude specific objects
Input Data
Input data is determined by the indices and time interval in the base settings.
Output Data
As a result of the algorithm execution, several records appear in the results index. Each record contains statistics for all time intervals for the processed fields.
_meta.calculation.id- the identifier of the algorithm setting in the profiling policy_meta.calculation.type- the type of algorithm_meta.execution.start_time- the time the profiling policy was launched_meta.execution.id- the identifier of the profiling policy launch_meta.object.identity- an array of UBA object identifiers_meta.object.id- the technical identifier of the UBA object_calculation- the result of the algorithm execution_calculation.extended_stats- extended statistics for all intervals_calculation.percentiles- percentiles for all intervals_calculation.span- the size of the interval_calculation.by_fields- combination of values of the processed fields for which statistics were calculated
Example of a JSON Result Object
{
"_index": "repeating_policy",
"_id": "HP9MmY4BcdU8iNUUlvMz",
"_score": 8.92765,
"_source": {
"_meta": {
"calculation": {
"id": "oTHfW44BwooGBkrZbNg_",
"type": "repeating"
},
"execution": {
"start_time": "2024-04-01T10:55:16.761Z",
"id": "DP9MmY4BcdU8iNUUlfMZ"
},
"object": {
"identity": [
"smith.a@saf.com",
"1456278811",
"smith.a"
],
"id": "9186db972bafeafed6411ab644d0313bb1def204"
}
},
"_calculation": {
"extended_stats": {
"count": 25,
"min": 4,
"max": 62,
"avg": 47.24,
"sum": 1181,
"sum_of_squares": 58917,
"variance": 125.06239999999991,
"variance_population": 125.06239999999991,
"variance_sampling": 130.27333333333323,
"std_deviation": 11.183130152153282,
"std_deviation_population": 11.183130152153282,
"std_deviation_sampling": 11.413734416628644,
"std_deviation_bounds": {
"upper": 69.60626030430657,
"lower": 24.873739695693438,
"upper_population": 69.60626030430657,
"lower_population": 24.873739695693438,
"upper_sampling": 70.0674688332573,
"lower_sampling": 24.412531166742713
}
},
"percentiles": {
"values": {
"1.0": 4,
"5.0": 32,
"25.0": 44,
"50.0": 49,
"75.0": 53,
"95.0": 61,
"99.0": 62
}
},
"span": "1h",
"by_fields": {
"computer_name": "Lenovo V15"
}
}
}
}