Statistics
Calculates statistics on the actions of an object over a period of time. Used to detect anomalies, such as:
- the number of VPN connections in 20 minutes exceeded the standard metrics for the user
- the user sent an unusually large volume of emails in an hour
Algorithm Description
- General and temporal filters are applied to the source index data
- The data is divided into intervals
- For a field or the result of a script execution on each interval, the aggregation function specified in the algorithm settings is calculated. Overall, an array of numbers is obtained, where each number is the result of the aggregation function for the data in the interval
- Statistics are calculated for the array obtained in the previous step
Input Parameters
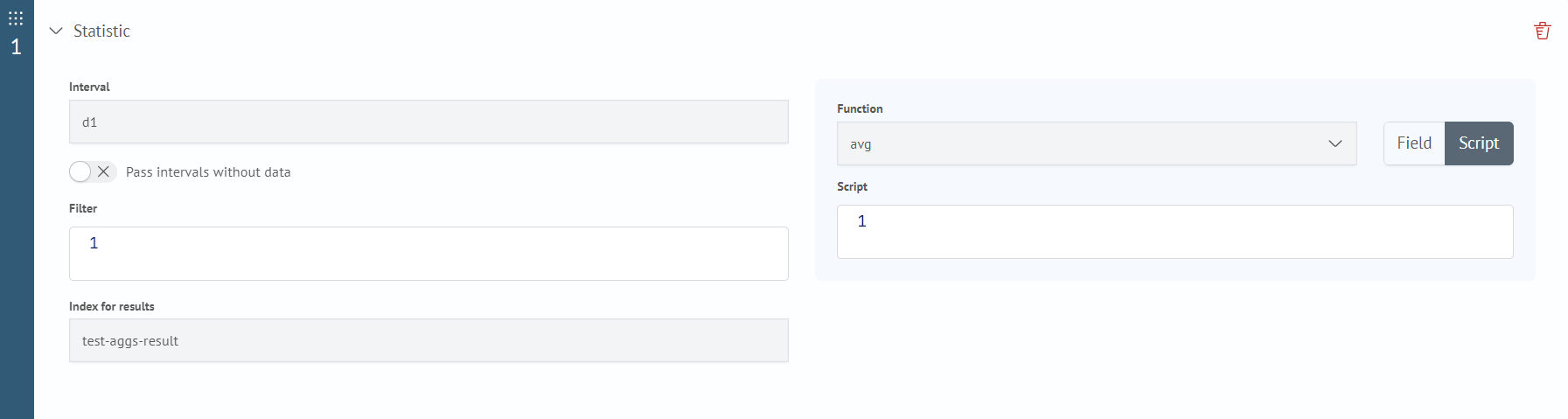
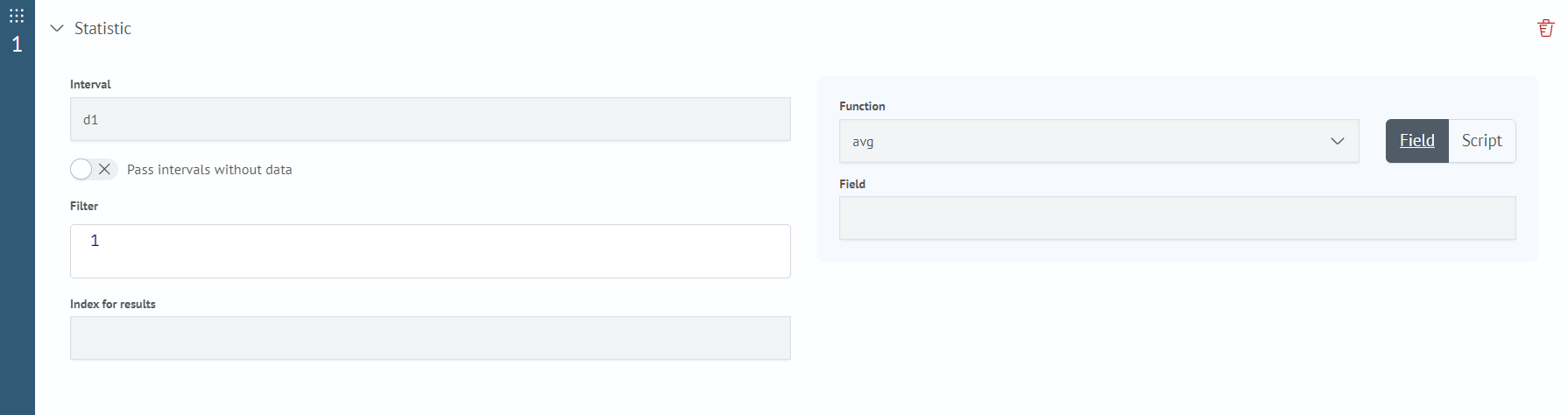
- Filter - general filter for sources (using expressions from the search command)
- Index for results - index where the execution results are recorded
- Interval - the size of the time intervals into which the source data is divided.
Examples of filling:
1yyear,1Mmonth,1dday,1Hhour,1mminute,1ssecond - Pass intervals without data - empty intervals are not considered in the statistics calculation
- Function - aggregation function. One of the functions:
- sum - sum
- min - minimum
- max - maximum
- avg - average
- dc - count of unique values
- count - number of events in the interval
- Script - painless script for calculating the numerical value of the function argument
- Field - the name of the numerical field of the data source, the value of which will be used as the function argument
Input Data
Input data is determined by the indices and time interval in the base settings.
Output Data
As a result of the algorithm execution, various statistics for all intervals appear in the results index.
_meta.calculation.id- the identifier of the algorithm setting in the profiling policy_meta.calculation.type- the type of algorithm_meta.execution.start_time- the time the profiling policy was launched_meta.execution.id- the identifier of the profiling policy launch_meta.object.identity- an array of UBA object identifiers_meta.object.id- the technical identifier of the UBA object_calculation- the result of the algorithm execution_calculation.extended_stats- extended statistics for all intervals_calculation.percentiles- percentiles for all intervals_calculation.span- the size of the interval
Example of a JSON Result Object
{
"_index": "test-aggs-result",
"_id": "_pOmmI4BtwOJADfCzSjL",
"_score": 8.713484,
"_source": {
"_meta": {
"calculation": {
"id": "1phiQY4BEuHUnGrO6ufe",
"type": "aggregation"
},
"execution": {
"start_time": "2024-04-01T07:54:12.203Z",
"id": "-ZOmmI4BtwOJADfCzShr"
},
"object": {
"identity": [
"smith.j@organization.com",
"19166788776",
"smith.j"
],
"id": "9186db972bafeafed6411ab644d0313bb1def204"
}
},
"_calculation": {
"extended_stats": {
"count": 2,
"min": 5,
"max": 5,
"avg": 5,
"sum": 10,
"sum_of_squares": 50,
"variance": 0,
"variance_population": 0,
"variance_sampling": 0,
"std_deviation": 0,
"std_deviation_population": 0,
"std_deviation_sampling": 0,
"std_deviation_bounds": {
"upper": 5,
"lower": 5,
"upper_population": 5,
"lower_population": 5,
"upper_sampling": 5,
"lower_sampling": 5
}
},
"percentiles": {
"values": {
"1.0": 5,
"5.0": 5,
"25.0": 5,
"50.0": 5,
"75.0": 5,
"95.0": 5,
"99.0": 5
}
},
"span": "1d"
}
}
}